
A few years ago, faking a screenshot took patience. You needed to edit a UI, match fonts, and hope nobody noticed the spacing was off by two pixels. Now you can generate a convincing “conversation” in under a minute, using a browser tool that already knows what iMessage bubbles look like and where Discord timestamps sit. That convenience is great for harmless uses (memes, storyboards, UX mockups), and terrible for everything else.
The result is a weird arms race: it is easier than ever to produce synthetic media, and also easier than ever to claim something is synthetic when it is not. That’s why “98% accurate” AI detection headlines feel comforting. They shouldn’t. They should make you ask: 98% of what, under which conditions, and with what mistakes?
Let’s unpack what a number like 98.7% detection accuracy can and cannot promise, in practical terms.
The new baseline: synthetic media is cheap, fast, and UI-perfect
There’s a particular flavor of “fake” that has become more common than deepfakes: the fake chat screenshot. Not because it is technically sophisticated, but because it is socially potent. A fabricated DM can ruin a friendship, “confirm” a rumor, or give a scammer just enough credibility to get a victim to click.
Tools exist that deliberately lower the friction. A generator can spit out a polished WhatsApp thread, complete with profile photos and read receipts, for a comedy sketch or a classroom example. If you want to see how turnkey this has become, a fake whatsapp chat generator is a perfect demo: the interface bakes in the design language, so the user focuses only on the words.
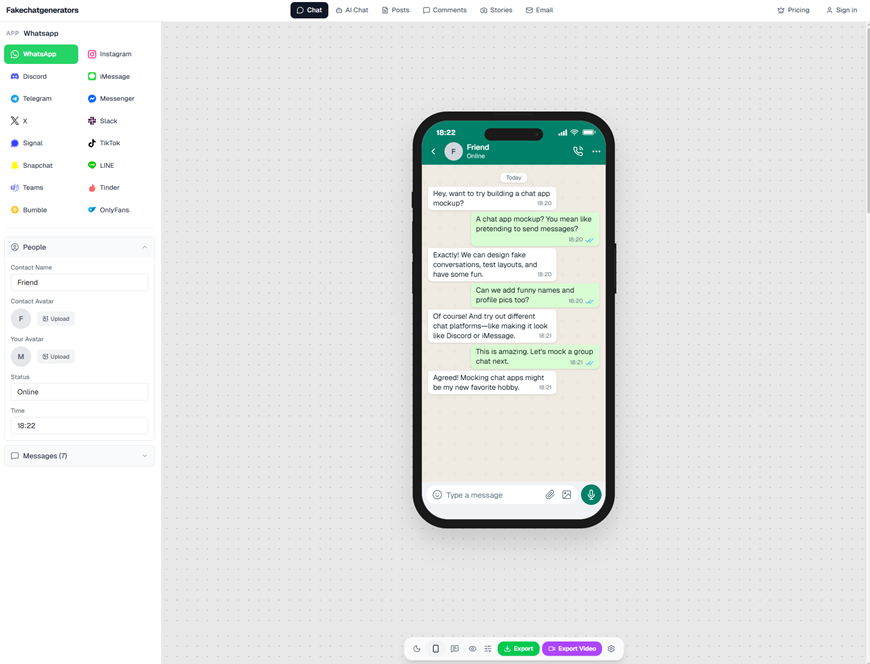
fakechatgenerators.com lets you mock up chat screenshots across 16 platforms
From a detector’s perspective, that’s already a warning label. Some synthetic media is born from diffusion models and GANs. Some is “just” templated UI graphics plus typed text. Those are different forensics problems, and accuracy claims may blur them together.
What “98.7% accuracy” is actually summarizing
When a vendor says “98.7% detection accuracy across 50+ generative models,” they’re compressing a lot of decisions into one tidy headline number. It may be technically honest and still easy to misread.
An accuracy figure usually depends on:
- The dataset: what images were tested, and whether they resemble the messy content you’ll see in production.
- The label definition: what counts as “AI-generated”? Fully synthetic images only, or also AI-edited photos, AI upscales, AI background replacements, or screenshots?
- The threshold: detectors output scores. You choose a cutoff. That choice moves the balance between false positives and false negatives.
- The base rate: how often AI images appear in your actual stream. Accuracy can look great in a balanced test set and behave badly in the real world.
This matters because the phrase “98% accurate” often gets interpreted as “it’s basically always right.” In detection work, “almost always” can still produce a pile of wrong calls when you process millions of items.
The confusion matrix: the four outcomes that matter
If you strip away the marketing, an AI image detector is a binary classifier: “AI” or “not AI.” That creates four possible outcomes:
- True positive (TP): AI image flagged as AI.
- False positive (FP): real image flagged as AI.
- True negative (TN): real image left alone.
- False negative (FN): AI image missed.
“Accuracy” is simply (TP + TN) / (TP + TN + FP + FN). It is the least informative metric when the real world is imbalanced, which it almost always is.
Two other measures tend to be more operationally meaningful:
- Precision: of the things you flagged as AI, how many were actually AI? Low precision means you are accusing real images.
- Recall (sensitivity): of the AI images, how many did you catch? Low recall means synthetic content slips through.
A single accuracy percentage can hide an uncomfortable truth: you can get high accuracy while being bad at the thing you care about, depending on what’s common.
A concrete example: base rates make “98%” feel different
Imagine a marketplace that processes 1,000,000 images per day. Suppose only 1% of uploads are AI-generated (10,000 images). Now pretend a detector has 98% accuracy in a lab evaluation. What happens next depends on where the errors fall.
If we oversimplify and assume the system makes errors evenly (it won’t, but this is illustrative), 2% of 1,000,000 is 20,000 mistakes per day. That’s already not small.
Now look at the human impact:
- If a meaningful chunk of those mistakes are false positives, you may end up wrongly blocking real sellers, legitimate journalists, or users posting authentic photos.
- If the mistakes skew toward false negatives, you get a quiet failure, synthetic media passes as real, and the platform’s trust erodes anyway.
This is why serious deployments treat “accuracy” as a starting point, not the decision rule.
“Across 50+ models” is reassuring, and also complicated
Generative image models are not a single target. Midjourney output has a different signature profile than a Stable Diffusion workflow with heavy post-processing. Flux and Ideogram add their own quirks. GAN-based imagery can show different artifacts than diffusion.
So “tested across 50+ generative models” implies coverage. It suggests the detector isn’t overfitting to one model’s fingerprints.
But there’s a catch: the real world includes things that aren’t on the test roster.
- People run img2img edits, inpainting, outpainting, and aggressive upscales.
- Content gets resaved, compressed, cropped, screenshotted, and watermarked.
- Platforms apply their own transformations. A “simple” repost can alter the byte-level evidence detectors like to use.
A model list is useful, but it is not the map of the territory. The important question is how accuracy holds up after the kinds of transformations your pipeline introduces.
Latency numbers (like sub-150ms) tell you where the tool fits
Speed sounds like a pure win, but it also hints at the product’s intended use. Sub-150ms latency suggests an API designed for high-throughput moderation, fraud screening, or newsroom workflows where you want a near-real-time signal.
That kind of latency is compatible with:
- Pre-publication checks in a CMS
- Automated triage queues for trust and safety teams
- Inline flags for marketplaces or banks
It is less compatible with slow, artisanal forensic work. If your case requires sensor noise analysis, provenance tracking, or multi-step examination across an image’s edit history, you probably need more than a single fast classifier call.
None of this is bad. It’s just category clarity. A fast detector is a smoke alarm, not a fire investigator.
What an AI image detector can reasonably claim to detect
A modern detector might handle multiple tasks beyond “AI or not,” such as NSFW detection, violence, and document tampering. That’s attractive because real incidents are rarely neat. A single suspicious asset might combine synthetic imagery with text overlays and doctored IDs.
A tool like an ai image detector typically sells itself to journalists, moderation teams, marketplaces, banks, and legal groups precisely because these environments need broad coverage and consistent scoring.
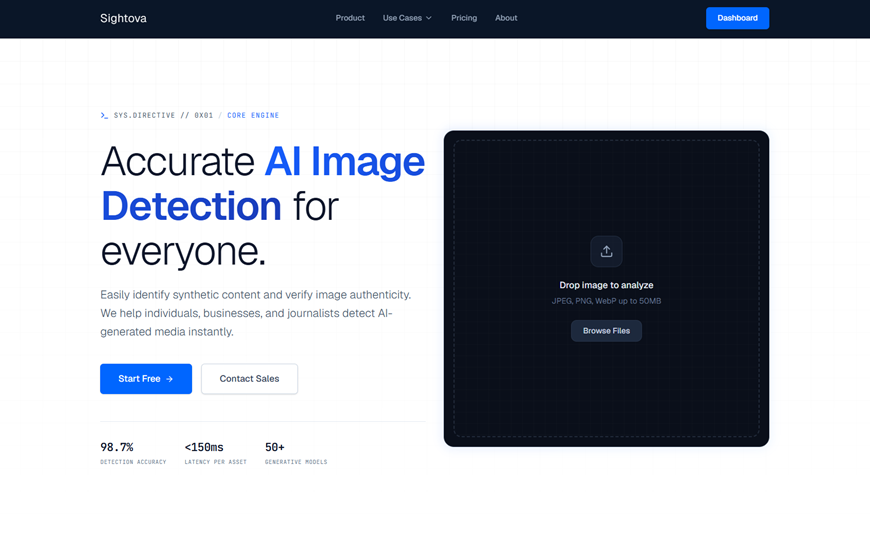
sightova.com flags AI-generated, tampered, NSFW, and violent imagery in milliseconds
But bundling tasks can also muddy interpretation. “98.7% detection accuracy” might refer to AI generation detection specifically, not to NSFW or tampering. Or it might be an aggregate across tasks. Without the metric breakdown, you should assume the number is a headline, not a contract.
The two error types have very different costs
False positives and false negatives are not symmetric. They hurt in different ways, and different industries will bias toward different tradeoffs.
False positives: the reputational and legal tax
Flagging a real image as AI-generated can:
- Undermine a journalist’s credibility if an authentic photo is publicly questioned
- Trigger takedowns that look like censorship
- Create liability if a platform penalizes users incorrectly
- Waste investigator time as teams chase ghosts
The operational fix is usually not “lower the threshold until it stops.” That can backfire. Instead, you build a review pathway: when the score is high but stakes are high too, route to a human or require additional evidence.
False negatives: the quiet leak
Missing AI-generated images can:
- Enable fraud (fake product listings, synthetic receipts, fabricated “proof” screenshots)
- Amplify misinformation (synthetic imagery used as “eyewitness” content)
- Weaken deterrence (attackers learn your filters are porous)
False negatives often feel less visible until an incident happens, at which point everyone asks why the system “failed,” even if it was doing exactly what its threshold policy instructed it to do.
“Document tampering” is a different beast than “AI-generated”
People lump these together because the consequences are similar, but the technical problem isn’t.
- AI-generated media detection often looks for statistical patterns left by model pipelines.
- Document tampering can involve copy-paste edits, text replacement, recompression artifacts, mismatched lighting, or inconsistent metadata.
A clean fraud operation might use no generative model at all. It might simply edit a PDF screenshot and resave it. Conversely, an AI model can generate a “document” that never existed, which is a synthesis problem, not tampering.
So when you evaluate a detector, separate the buckets. Ask: is the tool good at spotting synthetic imagery, good at spotting altered documents, or both? And how does it report uncertainty?
Screenshots are a natural enemy of detectors
Remember that fake chat screenshot problem. A screenshot is already a lossy transformation. It strips metadata and bakes everything into pixels. If the original content was AI-generated, the screenshot can destroy some evidence. If the original was real, the screenshot can introduce artifacts that look suspicious.
Then there’s the UI template issue: a fake chat generator produces imagery that looks like a real app because it is designed to. The “synthetic” part might be the conversation content, not the pixels. A detector focused on pixel-level generative artifacts may not be the right tool for that job.
This is where teams get tripped up. They buy an “AI image detector” expecting it to solve “authenticity” in the human sense. But authenticity is contextual. Pixels can be pristine while the story is false.
How to read a detection score like a careful adult
Most detectors output a probability-like score. People want that to mean “chance it’s AI.” Sometimes it is calibrated that way. Often it is not. It might be a confidence score relative to the training distribution.
In practice, treat the score as a signal to combine with other signals:
- Source reputation and chain of custody
- Reverse image checks inside your own systems (not public links, just internal duplication detection)
- Consistency with known events, locations, and timelines
- Presence of telltale prompt artifacts (weird text, impossible hands), while remembering those are not definitive
A strong workflow uses the detector to prioritize attention, not to declare final truth.
So what does “98% accurate” mean for you?
If you are deploying AI detection in a newsroom, a marketplace, or a trust and safety pipeline, “98.7% accuracy” can mean: this tool is likely solid in controlled evaluations across many popular generators, and it is fast enough to run at scale. That is valuable.
It does not mean:
- Every flagged image is definitely AI
- Every AI image will be caught
- The tool solves screenshot fakery, document fraud, or narrative manipulation by itself
- You can skip policy work (thresholds, appeals, audit logs, reviewer training)
The more consequential the decision, the more you should demand metrics that match the decision: precision at a given threshold, recall under typical transformations (compression, crops, screenshots), and performance by content type (photos, illustrations, documents, memes).
The odd comfort of a single percentage is that it feels like certainty. The reality is messier, but also manageable. A detector is a component. The system is the policy, the pipeline, and the humans who know when a score is a warning and when it is a verdict.